## 🎙️ VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
[](https://github.com/OpenBMB/VoxCPM/) [](https://arxiv.org/abs/2509.24650)[](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo) [](https://openbmb.github.io/VoxCPM-demopage)
#### VoxCPM1.5 Model Weights
[](https://huggingface.co/openbmb/VoxCPM1.5) [](https://modelscope.cn/models/OpenBMB/VoxCPM1.5)
👋 Contact us on [WeChat](assets/wechat.png)
## News
* [2025.12.05] 🎉 🎉 🎉 We Open Source the VoxCPM1.5 [weights](https://huggingface.co/openbmb/VoxCPM1.5)! The model now supports both full-parameter fine-tuning and efficient LoRA fine-tuning, empowering you to create your own tailored version. See [Release Notes](docs/release_note.md) for details.
* [2025.09.30] 🔥 🔥 🔥 We Release VoxCPM [Technical Report](https://arxiv.org/abs/2509.24650)!
* [2025.09.16] 🔥 🔥 🔥 We Open Source the VoxCPM-0.5B [weights](https://huggingface.co/openbmb/VoxCPM-0.5B)!
* [2025.09.16] 🎉 🎉 🎉 We Provide the [Gradio PlayGround](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo) for VoxCPM-0.5B, try it now!
## Overview
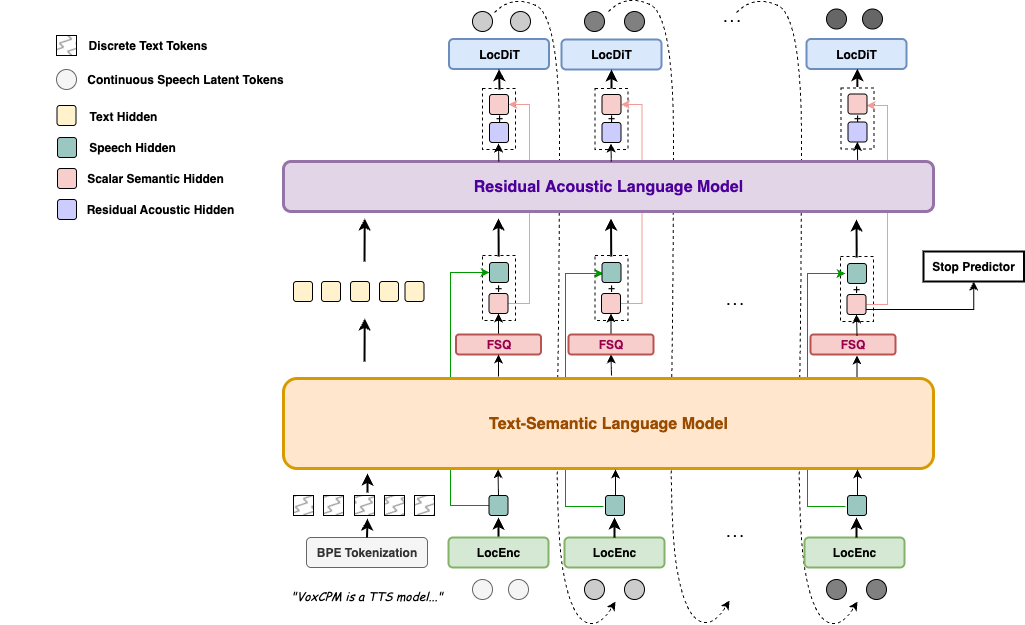
VoxCPM is a novel tokenizer-free Text-to-Speech (TTS) system that redefines realism in speech synthesis. By modeling speech in a continuous space, it overcomes the limitations of discrete tokenization and enables two flagship capabilities: context-aware speech generation and true-to-life zero-shot voice cloning.
Unlike mainstream approaches that convert speech to discrete tokens, VoxCPM uses an end-to-end diffusion autoregressive architecture that directly generates continuous speech representations from text. Built on [MiniCPM-4](https://huggingface.co/openbmb/MiniCPM4-0.5B) backbone, it achieves implicit semantic-acoustic decoupling through hierachical language modeling and FSQ constraints, greatly enhancing both expressiveness and generation stability.
### 🚀 Key Features
- **Context-Aware, Expressive Speech Generation** - VoxCPM comprehends text to infer and generate appropriate prosody, delivering speech with remarkable expressiveness and natural flow. It spontaneously adapts speaking style based on content, producing highly fitting vocal expression trained on a massive 1.8 million-hour bilingual corpus.
- **True-to-Life Voice Cloning** - With only a short reference audio clip, VoxCPM performs accurate zero-shot voice cloning, capturing not only the speaker's timbre but also fine-grained characteristics such as accent, emotional tone, rhythm, and pacing to create a faithful and natural replica.
- **High-Efficiency Synthesis** - VoxCPM supports streaming synthesis with a Real-Time Factor (RTF) as low as 0.17 on a consumer-grade NVIDIA RTX 4090 GPU, making it possible for real-time applications.
### 📦 Model Versions
See [Release Notes](docs/release_note.md) for details
- **VoxCPM1.5** (Latest):
- Model Params: 750M
- Sampling rate of AudioVAE: 44100
- Token rate in LM Backbone: 6.25Hz (patch-size=4)
- RTF in a single NVIDIA-RTX 4090 GPU: ~0.15
- **VoxCPM-0.5B** (Original):
- Model Params: 600M
- Sampling rate of AudioVAE: 16000
- Token rate in LM Backbone: 12.5Hz (patch-size=2)
- RTF in a single NVIDIA-RTX 4090 GPU: 0.17
## Quick Start
### 🔧 Install from PyPI
``` sh
pip install voxcpm
```
### 1. Model Download (Optional)
By default, when you first run the script, the model will be downloaded automatically, but you can also download the model in advance.
- Download VoxCPM1.5
```
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM1.5")
```
- Or Download VoxCPM-0.5B
```
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B")
```
- Download ZipEnhancer and SenseVoice-Small. We use ZipEnhancer to enhance speech prompts and SenseVoice-Small for speech prompt ASR in the web demo.
```
from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')
```
### 2. Basic Usage
```python
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM1.5")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool, but will disable native raw text support
denoise=True, # enable external Denoise tool, but it may cause some distortion and restrict the sampling rate to 16kHz
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, model.tts_model.sample_rate)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, model.tts_model.sample_rate)
print("saved: output_streaming.wav")
```
### 3. CLI Usage
After installation, the entry point is `voxcpm` (or use `python -m voxcpm.cli`).
```bash
# 1) Direct synthesis (single text)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." --output out.wav
# 2) Voice cloning (reference audio + transcript)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--output out.wav \
--denoise
# (Optinal) Voice cloning (reference audio + transcript file)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-file "/path/to/text-file" \
--output out.wav \
--denoise
# 3) Batch processing (one text per line)
voxcpm --input examples/input.txt --output-dir outs
# (optional) Batch + cloning
voxcpm --input examples/input.txt --output-dir outs \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--denoise
# 4) Inference parameters (quality/speed)
voxcpm --text "..." --output out.wav \
--cfg-value 2.0 --inference-timesteps 10 --normalize
# 5) Model loading
# Prefer local path
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
# Or from Hugging Face (auto download/cache)
voxcpm --text "..." --output out.wav \
--hf-model-id openbmb/VoxCPM1.5 --cache-dir ~/.cache/huggingface --local-files-only
# 6) Denoiser control
voxcpm --text "..." --output out.wav \
--no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
# 7) Help
voxcpm --help
python -m voxcpm.cli --help
```
### 4. Start web demo
You can start the UI interface by running `python app.py`, which allows you to perform Voice Cloning and Voice Creation.
### 5. Fine-tuning
VoxCPM1.5 supports both full fine-tuning (SFT) and LoRA fine-tuning, allowing you to train personalized voice models on your own data. See the [Fine-tuning Guide](docs/finetune.md) for detailed instructions.
**Quick Start:**
```bash
# Full fine-tuning
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v1.5/voxcpm_finetune_all.yaml
# LoRA fine-tuning
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v1.5/voxcpm_finetune_lora.yaml
```
## 📚 Documentation
- **[Usage Guide](docs/usage_guide.md)** - Detailed guide on how to use VoxCPM effectively, including text input modes, voice cloning tips, and parameter tuning
- **[Fine-tuning Guide](docs/finetune.md)** - Complete guide for fine-tuning VoxCPM models with SFT and LoRA
- **[Release Notes](docs/release_note.md)** - Version history and updates
- **[Performance Benchmarks](docs/performance.md)** - Detailed performance comparisons on public benchmarks
---
## 📚 More Information
### 🌟 Community Projects
We're excited to see the VoxCPM community growing! Here are some amazing projects and features built by our community:
- **[ComfyUI-VoxCPM](https://github.com/wildminder/ComfyUI-VoxCPM)** A VoxCPM extension for ComfyUI.
- **[ComfyUI-VoxCPMTTS](https://github.com/1038lab/ComfyUI-VoxCPMTTS)** A VoxCPM extension for ComfyUI.
- **[WebUI-VoxCPM](https://github.com/rsxdalv/tts_webui_extension.vox_cpm)** A template extension for TTS WebUI.
- **[PR: Streaming API Support (by AbrahamSanders)](https://github.com/OpenBMB/VoxCPM/pull/26)**
- **[VoxCPM-NanoVLLM](https://github.com/a710128/nanovllm-voxcpm)** NanoVLLM integration for VoxCPM for faster, high-throughput inference on GPU.
- **[VoxCPM-ONNX](https://github.com/bluryar/VoxCPM-ONNX)** ONNX export for VoxCPM supports faster CPU inference.
- **[VoxCPMANE](https://github.com/0seba/VoxCPMANE)** VoxCPM TTS with Apple Neural Engine backend server.
*Note: The projects are not officially maintained by OpenBMB.*
*Have you built something cool with VoxCPM? We'd love to feature it here! Please open an issue or pull request to add your project.*
### 📊 Performance Highlights
VoxCPM achieves competitive results on public zero-shot TTS benchmarks. See [Performance Benchmarks](docs/performance.md) for detailed comparison tables.
## ⚠️ Risks and limitations
- General Model Behavior: While VoxCPM has been trained on a large-scale dataset, it may still produce outputs that are unexpected, biased, or contain artifacts.
- Potential for Misuse of Voice Cloning: VoxCPM's powerful zero-shot voice cloning capability can generate highly realistic synthetic speech. This technology could be misused for creating convincing deepfakes for purposes of impersonation, fraud, or spreading disinformation. Users of this model must not use it to create content that infringes upon the rights of individuals. It is strictly forbidden to use VoxCPM for any illegal or unethical purposes. We strongly recommend that any publicly shared content generated with this model be clearly marked as AI-generated.
- Current Technical Limitations: Although generally stable, the model may occasionally exhibit instability, especially with very long or expressive inputs. Furthermore, the current version offers limited direct control over specific speech attributes like emotion or speaking style.
- Bilingual Model: VoxCPM is trained primarily on Chinese and English data. Performance on other languages is not guaranteed and may result in unpredictable or low-quality audio.
- This model is released for research and development purposes only. We do not recommend its use in production or commercial applications without rigorous testing and safety evaluations. Please use VoxCPM responsibly.
---
## 📝 TO-DO List
Please stay tuned for updates!
- [x] Release the VoxCPM technical report.
- [x] Support higher sampling rate (44.1kHz in VoxCPM-1.5).
- [x] Support SFT and LoRA fine-tuning.
- [] Multilingual Support (besides ZH/EN).
- [] Controllable Speech Generation by Human Instruction.
## 📄 License
The VoxCPM model weights and code are open-sourced under the [Apache-2.0](LICENSE) license.
## 🙏 Acknowledgments
We extend our sincere gratitude to the following works and resources for their inspiration and contributions:
- [DiTAR](https://arxiv.org/abs/2502.03930) for the diffusion autoregressive backbone used in speech generation
- [MiniCPM-4](https://github.com/OpenBMB/MiniCPM) for serving as the language model foundation
- [CosyVoice](https://github.com/FunAudioLLM/CosyVoice) for the implementation of Flow Matching-based LocDiT
- [DAC](https://github.com/descriptinc/descript-audio-codec) for providing the Audio VAE backbone
## Institutions
This project is developed by the following institutions:
-  [ModelBest](https://modelbest.cn/)
-
[ModelBest](https://modelbest.cn/)
-  [THUHCSI](https://github.com/thuhcsi)
## ⭐ Star History
[](https://star-history.com/#OpenBMB/VoxCPM&Date)
## 📚 Citation
If you find our model helpful, please consider citing our projects 📝 and staring us ⭐️!
```bib
@article{voxcpm2025,
title = {VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and Yu, Renjie and Wang, Ziyang and Ye, Runchuan and Sun, Weiyue and Gui, Jiancheng and Li, Kehan and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2509.24650},
year = {2025},
}
```
[THUHCSI](https://github.com/thuhcsi)
## ⭐ Star History
[](https://star-history.com/#OpenBMB/VoxCPM&Date)
## 📚 Citation
If you find our model helpful, please consider citing our projects 📝 and staring us ⭐️!
```bib
@article{voxcpm2025,
title = {VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and Yu, Renjie and Wang, Ziyang and Ye, Runchuan and Sun, Weiyue and Gui, Jiancheng and Li, Kehan and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2509.24650},
year = {2025},
}
```