# 🎙️ VoxCPM: 基于上下文感知和真实声音克隆的无 Tokenizer 语音合成系统
[](https://github.com/OpenBMB/VoxCPM/) [](https://arxiv.org/abs/2509.24650)[](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo) [](https://openbmb.github.io/VoxCPM-demopage)
👋 在 [微信](assets/wechat.png) 上联系我们
## 最新动态
* [2025.12.05] 🎉 🎉 🎉 开源 **VoxCPM1.5** [权重](https://huggingface.co/openbmb/VoxCPM1.5)!该模型现在支持全参数微调和高效的 LoRA 微调,使您能够创建自己的定制版本。详见 [发布说明](docs/release_note.md)。
* [2025.09.30] 🔥 🔥 🔥 发布 VoxCPM [技术报告](https://arxiv.org/abs/2509.24650)!
* [2025.09.16] 🔥 🔥 🔥 开源 VoxCPM-0.5B [权重](https://huggingface.co/openbmb/VoxCPM-0.5B)!
* [2025.09.16] 🎉 🎉 🎉 提供 VoxCPM-0.5B 的 [Gradio PlayGround](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo),立即试用!
## 项目概览
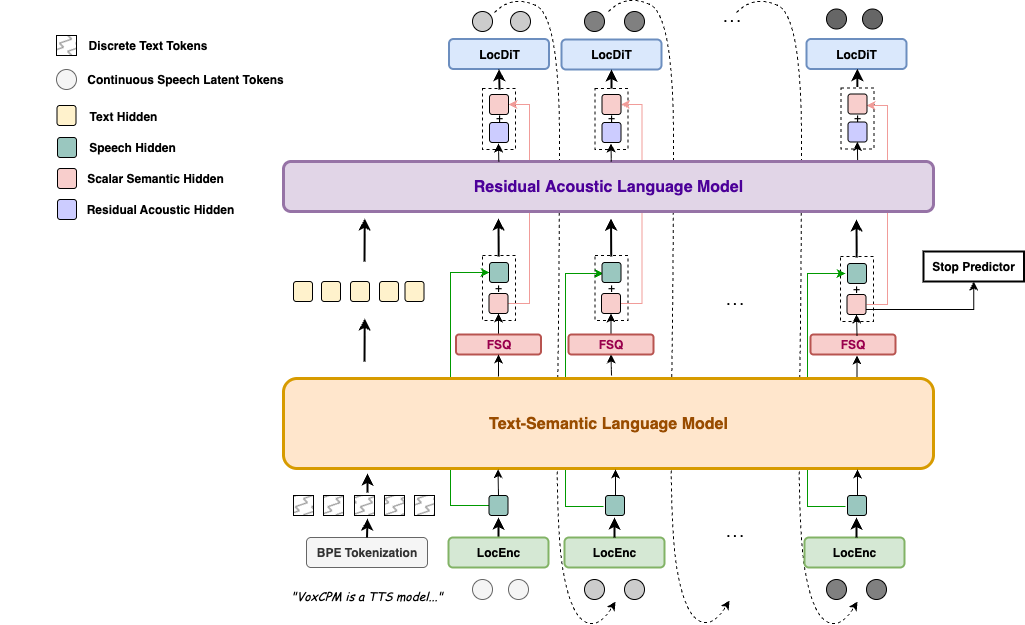
VoxCPM 是一种新颖的无 Tokenizer 文本转语音(TTS)系统,重新定义了语音合成的真实感。通过在连续空间中对语音进行建模,它克服了离散 Token 化带来的限制,并实现了两大核心能力:**上下文感知语音生成**和**逼真的零样本声音克隆**。
与将语音转换为离散 Token 的主流方法不同,VoxCPM 采用了端到端的扩散自回归架构,直接从文本生成连续的语音表示。基于 [MiniCPM-4](https://huggingface.co/openbmb/MiniCPM4-0.5B) 骨干网络,通过分层语言建模和 FSQ 约束实现了隐式的语义-声学解耦,极大地增强了表现力和生成稳定性。
### 🚀 核心特性
- **上下文感知、富有表现力的语音生成** - VoxCPM 能够理解文本并推断出适当的韵律,生成富有表现力和自然流畅的语音。它会根据内容自发调整说话风格,基于 180 万小时的双语语料库训练,产生高度贴合的语音表达。
- **逼真的声音克隆** - 仅需一段简短的参考音频,VoxCPM 就能进行准确的零样本声音克隆,不仅能捕捉说话者的音色,还能捕捉细微的特征,如口音、情感基调、节奏和语速,从而创建一个忠实且自然的复刻。
- **高效合成** - VoxCPM 支持流式合成,在消费级 NVIDIA RTX 4090 GPU 上,实时因子(RTF)低至 0.17,使实时应用成为可能。
### 📦 模型版本
详见 [发布说明](docs/release_note.md)
- **VoxCPM1.5** (最新):
- 模型参数: 800M
- AudioVAE 采样率: 44100
- LM 骨干网络 Token 率: 6.25Hz (patch-size=4)
- 单张 NVIDIA-RTX 4090 GPU RTF: ~0.15
- **VoxCPM-0.5B** (原始):
- 模型参数: 640M
- AudioVAE 采样率: 16000
- LM 骨干网络 Token 率: 12.5Hz (patch-size=2)
- 单张 NVIDIA-RTX 4090 GPU RTF: 0.17
## 快速开始
### 🔧 通过 PyPI 安装
```bash
pip install voxcpm
```
### 1. 模型下载(可选)
默认情况下,首次运行脚本时会自动下载模型,但您也可以提前下载模型。
- 下载 VoxCPM1.5
```python
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM1.5")
```
- 或下载 VoxCPM-0.5B
```python
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B")
```
- 下载 ZipEnhancer 和 SenseVoice-Small。我们使用 ZipEnhancer 来增强语音提示,并在 Web 演示中使用 SenseVoice-Small 进行语音提示的 ASR(自动语音识别)。
```python
from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')
```
### 2. 基本用法 (Python)
```python
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM1.5")
# 非流式生成
wav = model.generate(
text="VoxCPM 是 ModelBest 推出的一款创新型端到端 TTS 模型,旨在生成极具表现力的语音。",
prompt_wav_path=None, # 可选: 用于声音克隆的提示语音路径
prompt_text=None, # 可选: 参考文本
cfg_value=2.0, # LocDiT 的 LM 引导值,越高越贴合提示,但可能影响自然度
inference_timesteps=10, # LocDiT 推理步数,越高效果越好,越低速度越快
normalize=False, # 启用外部文本标准化工具,但会禁用原生原始文本支持
denoise=False, # 启用外部降噪工具,可能会导致一些失真并将采样率限制在 16kHz
retry_badcase=True, # 启用针对某些坏例的重试模式(不可中断)
retry_badcase_max_times=3, # 最大重试次数
retry_badcase_ratio_threshold=6.0, # 坏例检测的最大长度限制(简单但有效),对于慢节奏语音可调整
)
sf.write("output.wav", wav, model.tts_model.sample_rate)
print("已保存: output.wav")
# 流式生成
chunks = []
for chunk in model.generate_streaming(
text = "使用 VoxCPM 进行流式文本转语音非常简单!",
# 支持与上述相同的参数
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, model.tts_model.sample_rate)
print("已保存: output_streaming.wav")
```
### 3. 命令行 (CLI) 用法
安装后,入口点是 `voxcpm`(或使用 `python -m voxcpm.cli`)。
```bash
# 1) 直接合成 (单条文本)
voxcpm --text "VoxCPM 是一款创新的端到端 TTS 模型。" --output out.wav
# 2) 声音克隆 (参考音频 + 文本)
voxcpm --text "VoxCPM 是一款创新的端到端 TTS 模型。" \
--prompt-audio path/to/voice.wav \
--prompt-text "参考音频的文本内容" \
--output out.wav \
# --denoise
# (可选) 声音克隆 (参考音频 + 文本文件)
voxcpm --text "VoxCPM 是一款创新的端到端 TTS 模型。" \
--prompt-audio path/to/voice.wav \
--prompt-file "/path/to/text-file" \
--output out.wav \
# --denoise
# 3) 批量处理 (每行一条文本)
voxcpm --input examples/input.txt --output-dir outs
# (可选) 批量 + 克隆
voxcpm --input examples/input.txt --output-dir outs \
--prompt-audio path/to/voice.wav \
--prompt-text "参考音频的文本内容" \
# --denoise
# 4) 推理参数 (质量/速度)
voxcpm --text "..." --output out.wav \
--cfg-value 2.0 --inference-timesteps 10 --normalize
# 5) 模型加载
# 优先使用本地路径
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
# 或者从 Hugging Face 加载 (自动下载/缓存)
voxcpm --text "..." --output out.wav \
--hf-model-id openbmb/VoxCPM1.5 --cache-dir ~/.cache/huggingface --local-files-only
# 6) 降噪器控制
voxcpm --text "..." --output out.wav \
--no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
# 7) 帮助
voxcpm --help
python -m voxcpm.cli --help
```
### 4. 启动 Web 演示
您可以运行 `python app.py` 启动 UI 界面,该界面允许您执行声音克隆和声音创作。
```bash
python app.py
```
### 5. 微调 (Fine-tuning)
VoxCPM1.5 支持全参数微调 (SFT) 和 LoRA 微调,允许您在自己的数据上训练个性化的语音模型。详细说明请参阅 [微调指南](docs/finetune.md)。
**快速开始:**
```bash
# 全参数微调
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v1.5/voxcpm_finetune_all.yaml
# LoRA 微调
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v1.5/voxcpm_finetune_lora.yaml
```
## 📚 文档
- **[使用指南](docs/usage_guide.md)** - 关于如何有效使用 VoxCPM 的详细指南,包括文本输入模式、声音克隆技巧和参数调整。
- **[微调指南](docs/finetune.md)** - 使用 SFT 和 LoRA 微调 VoxCPM 模型的完整指南。
- **[发布说明](docs/release_note.md)** - 版本历史和更新。
- **[性能基准](docs/performance.md)** - 公共基准上的详细性能比较。
## ⚠️ 风险和限制
- **通用模型行为**: 虽然 VoxCPM 已在大规模数据集上进行了训练,但它仍可能产生意外的、有偏见的或包含伪影的输出。
- **声音克隆滥用的可能性**: VoxCPM 强大的零样本声音克隆能力可能会被滥用。
---